# 斯坦福编程范式 CS107_13
# 使用 GCC 解释器的例子
main.c 文件
#include <stdlib.h> | |
#include <> | |
#assert <assert.h> | |
int main(){ | |
void *mem = malloc(400); | |
assert(mem != NULL); | |
peintf("Yay! \n"); | |
free(mem); | |
return 0; | |
} |
上述 main 函数在 gcc 编译器后,生成 main.o 文件,然后进一步链接生成可执行文件。
main.o 文件
SP = SP - 4
CALL <malloc>
...
CALL <printf>
...
CALL <free>
RV = 0
SP = SP + 4
RET
如果我们把主函数中 第二行的 #include 注释掉,那么大多数编译器就会不知道 printf 函数的意义从而报错。但 GCC 编译器不会,GCC 会根据函数的调用方式尝试去匹配它的原型。GCC 看到 printf 里面只有一个字符串作为参数,它会发出一个警告,说没有找到 printf 函数的原型,但是它不会停下来,继续生成 .o 文件。解释器会去标准库中去寻找这些代码,而 printf malloc free 这些函数正是在标准库中。
如果把第三个 #assert 注释掉的话,编译器会猜测 assert 是一个函数,而不是一个宏定义,从而生成 .o 文件,而在链接阶段就会失败,因为 assert 不在标准库中,它不是一个函数。
# 另一个经典例子
int main(){ | |
int num = 65; | |
int length = strlen((char*)&num,num); | |
printf("Length = %d\n",length); | |
return 0; | |
} |
我们没有声明 strlen 的函数原型,gcc 编译器会忽略继续编码,并在链接阶段去标准库中去链接同名的函数,虽然同名的函数只有 1 个参数,但是链接过程不会去管参数个数,而只会去查看参数类型。因为 strlen 只有一个函数参数,strlen 从 65 下方开始进行处理,即 (char *)&num,符合函数 strlen 函数的参数类型,因此可以继续进行链接运行,strlen 函数不会使用 65 变量。
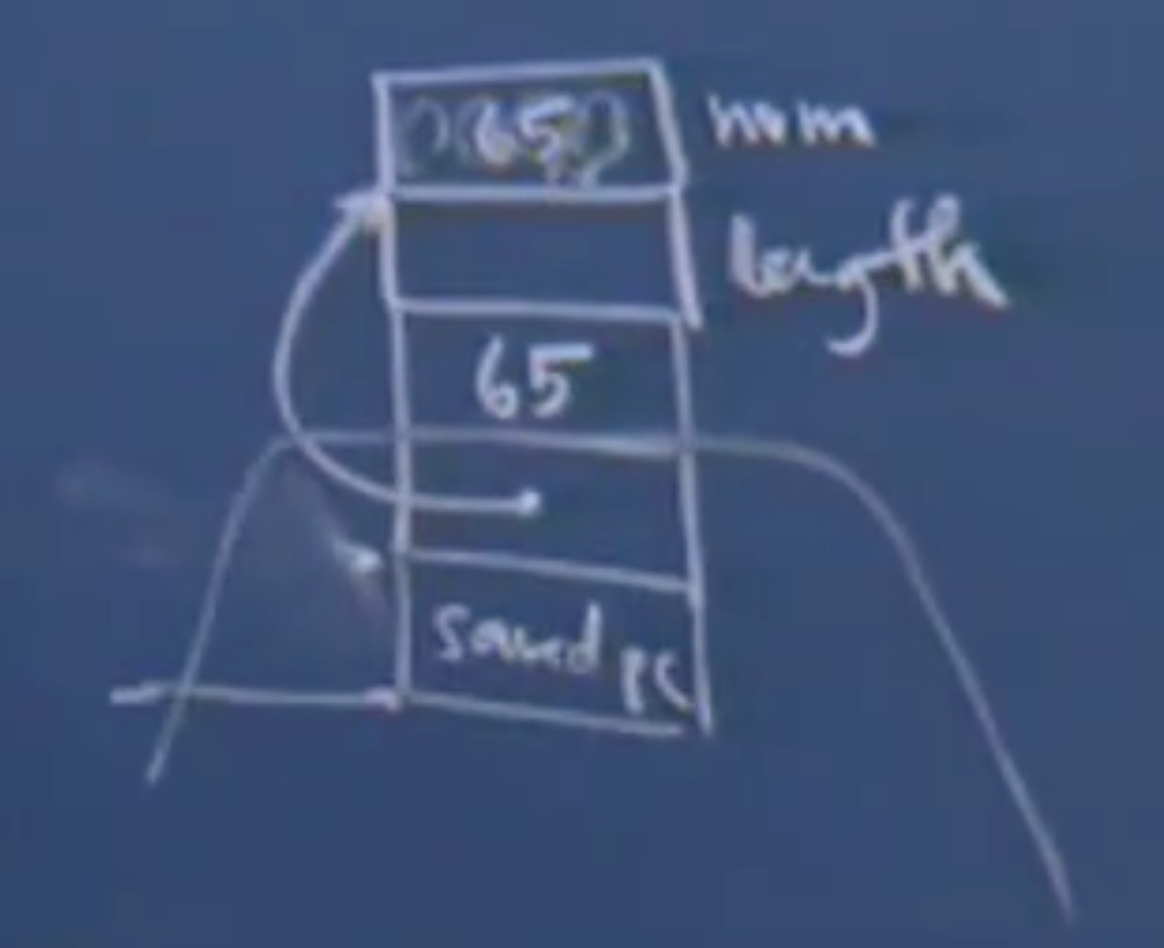
这样子写会在编译过程中产生警告,如果想要不产生这样的警告,我们可以手动定义一个原型。这种写法相较于写 #include 来说,include 是包涵所有的 .h 文件,是很大很大的,这对编译很不利,可以手动添加原型来实现要求,而不需要添加 include 文件。当然这样也有风险,如果写错的话,那么编译出来的东西并不是你想要的代码。
那么这样的代码输出的 Length 是多少?答案是 0 或 1。如果是大端存储,那么 int 的 4 字节对应的 char 就是:0 0 0 ‘A’,那么 strlen 就认为这个字符串以 0 开头,那么它就是一个空的字符串,所以返回 0。如果是小端存储,那么 4 字节就是 ‘A’ 0 0 0,那么就是字符串长度就是 1。
int strlen(char *s,int len); | |
int main(){ | |
int num = 65; | |
int length = strlen((char*)&num,num); | |
printf("Length = %d\n",length); | |
return 0; | |
} |
# 经典例子相反的例子
一个原先要传递三个参数的函数,如果我声明原型并只传入一个参数会怎么样?
int memcmp(void *v1); | |
int main() | |
{ | |
int n = 17; | |
int m = memcmp(&n); | |
} |
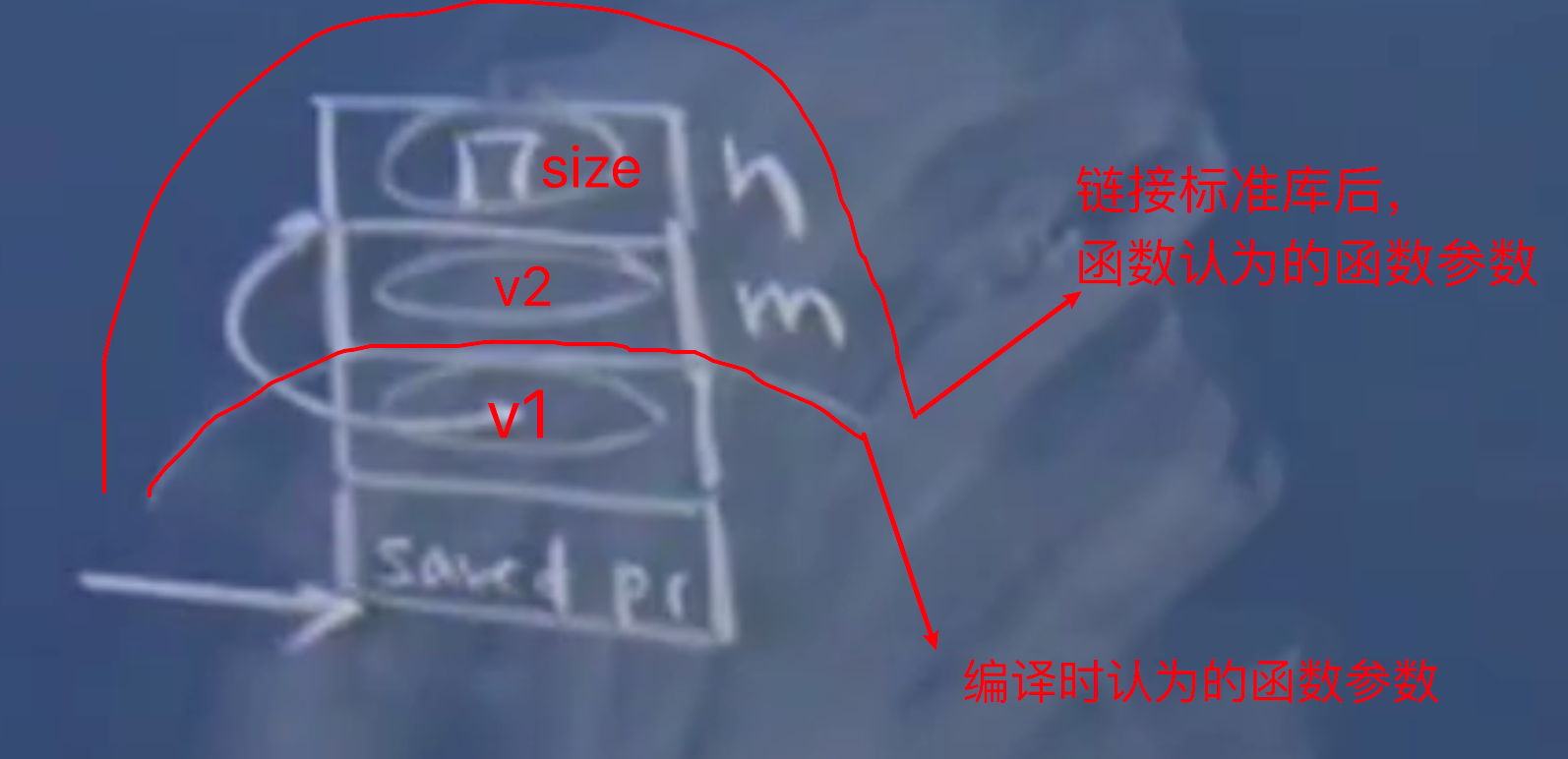
这样子调用很不合理,但实际上运行就是这样。并且很有可能在运行过程中崩溃,因为 v2 部分没有被初始化,是一个随意的 4 字节地址,不太可能是一个合法的栈指针或者堆指针等等,如果是的话,那就碰巧能跑起来。
在 C++ 中因为更多的使用模版等内容,不太经常和指针打交道,更不容易崩溃。
纯 C 语言的编译是 CALL <memcmp>
C ++ 中的语言编译会关注参数,使用不同的签名,对多个版本的 memcmp 进行消歧 ,我们定义的函数就是 CALL <memcmp_void_p> ,而标准库中的函数就是 CALL <memcmp_void_p_void_p_int> ,从这个角度来看 C++ 会更加安全。
# 举一些为什么程序会崩溃的小例子
# seg fault (段错误):
常出现在对错误的指针进行解引用。如 *(NULL)
# bus errors(总线错误):
void *vp = ____; | |
*(short *)vp = 7; |
内存地址从上到下分为四部分:Data 段、Stack 段、Heap 段、Code 段。栈和堆中内存要求首地址都是 4 字节对齐的。如果 vp 就是四个部分中的某部分,那我们有 50% 的可能性得到错误,如果没有报错的话,就说明 vp 是某两个字节的内存块。
*(int *)vp = 55; |
上述地址也是不合法的,因为 int 类型的地址必须是 4 的倍数。
# 缓冲区溢出
# 一个数组越界例子
对于这段代码,i = 4 的时候,array [4] = 0 即将 i 地址的内容重新赋值为 0,因此程序会不断的进行循环。这种错误被称为缓冲区溢出。
int main(){ | |
int i; | |
int array[4]; | |
for(i = 0;i <= 4;i++){ | |
array[i] = 0; | |
} | |
return 0; | |
} |
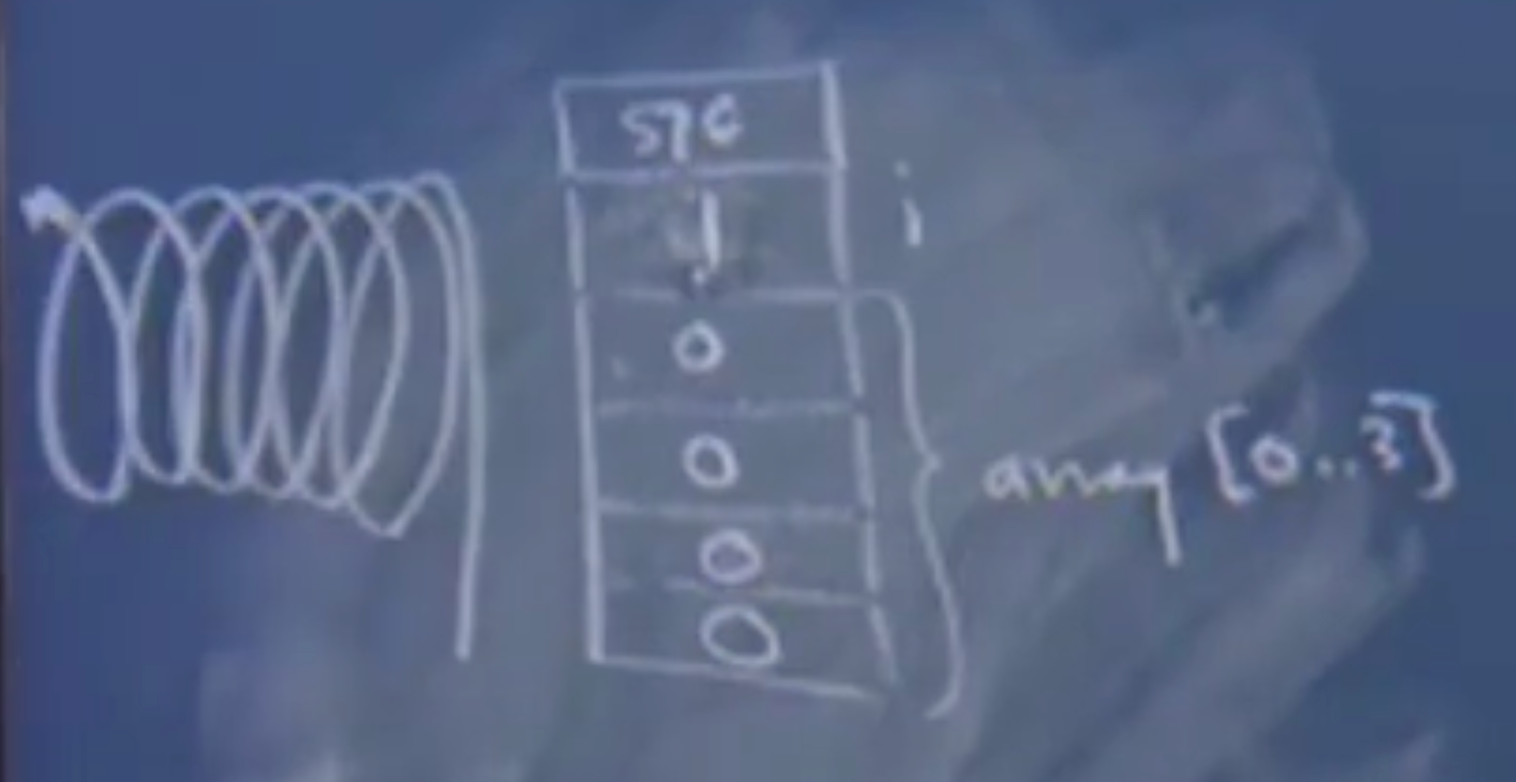
# 一个数组越界例子(改为 short 数组)
int main(){ | |
int i; | |
short array[4]; | |
for(i = 0;i <= 4;i++){ | |
array[i] = 0; | |
} | |
return 0; | |
} |
这样的代码在运行阶段可能不会陷入死循环。
大端存储不会陷入死循环,只是会多进行一次赋值操作。
小端存储就会陷入死循环,原因和前面的 int 数组的原因是一样的:

# 一个之前期中考试的例子
void foo(){ | |
int array[4]; | |
int i; | |
for(i = 0;i<=4;i++){ | |
array[i] -= 4; | |
} | |
} |
数组越界后,会擅自对 saved PC 的值减 4。
